publications
2024
-
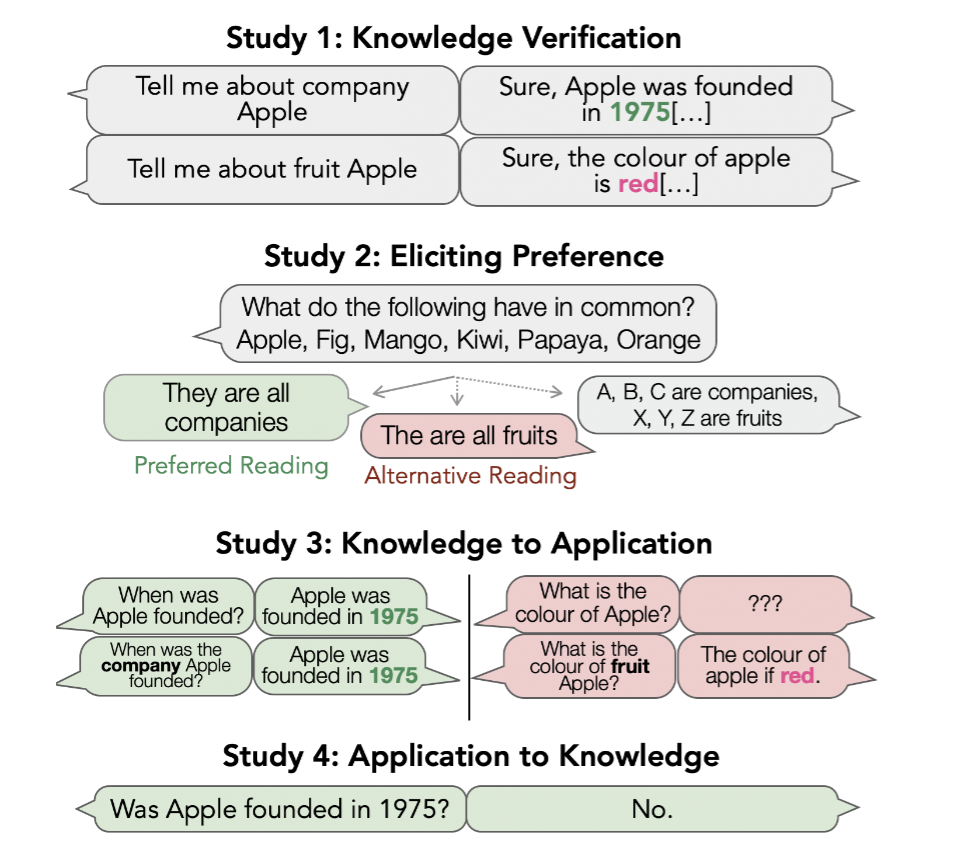 To Know or Not To Know? Analyzing Self-Consistency of Large Language Models under AmbiguityAnastasiia Sedova, Robert Litschko, Diego Frassinelli, and 2 more authorsIn Findings of the Association for Computational Linguistics: EMNLP 2024, Nov 2024
To Know or Not To Know? Analyzing Self-Consistency of Large Language Models under AmbiguityAnastasiia Sedova, Robert Litschko, Diego Frassinelli, and 2 more authorsIn Findings of the Association for Computational Linguistics: EMNLP 2024, Nov 2024One of the major aspects contributing to the striking performance of large language models (LLMs) is the vast amount of factual knowledge accumulated during pre-training. Yet, many LLMs suffer from self-inconsistency, which raises doubts about their trustworthiness and reliability. This paper focuses on entity type ambiguity, analyzing the proficiency and consistency of state-of-the-art LLMs in applying factual knowledge when prompted with ambiguous entities. To do so, we propose an evaluation protocol that disentangles knowing from applying knowledge, and test state-of-the-art LLMs on 49 ambiguous entities. Our experiments reveal that LLMs struggle with choosing the correct entity reading, achieving an average accuracy of only 85%, and as low as 75% with underspecified prompts. The results also reveal systematic discrepancies in LLM behavior, showing that while the models may possess knowledge, they struggle to apply it consistently, exhibit biases toward preferred readings, and display self-inconsistencies. This highlights the need to address entity ambiguity in the future for more trustworthy LLMs.
@inproceedings{sedova-etal-2024-know, title = {To Know or Not To Know? Analyzing Self-Consistency of Large Language Models under Ambiguity}, author = {Sedova, Anastasiia and Litschko, Robert and Frassinelli, Diego and Roth, Benjamin and Plank, Barbara}, booktitle = {Findings of the Association for Computational Linguistics: EMNLP 2024}, month = nov, year = {2024}, address = {Miami, Florida, USA}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2024.findings-emnlp.1003/}, doi = {10.18653/v1/2024.findings-emnlp.1003}, pages = {17203--17217}, } -
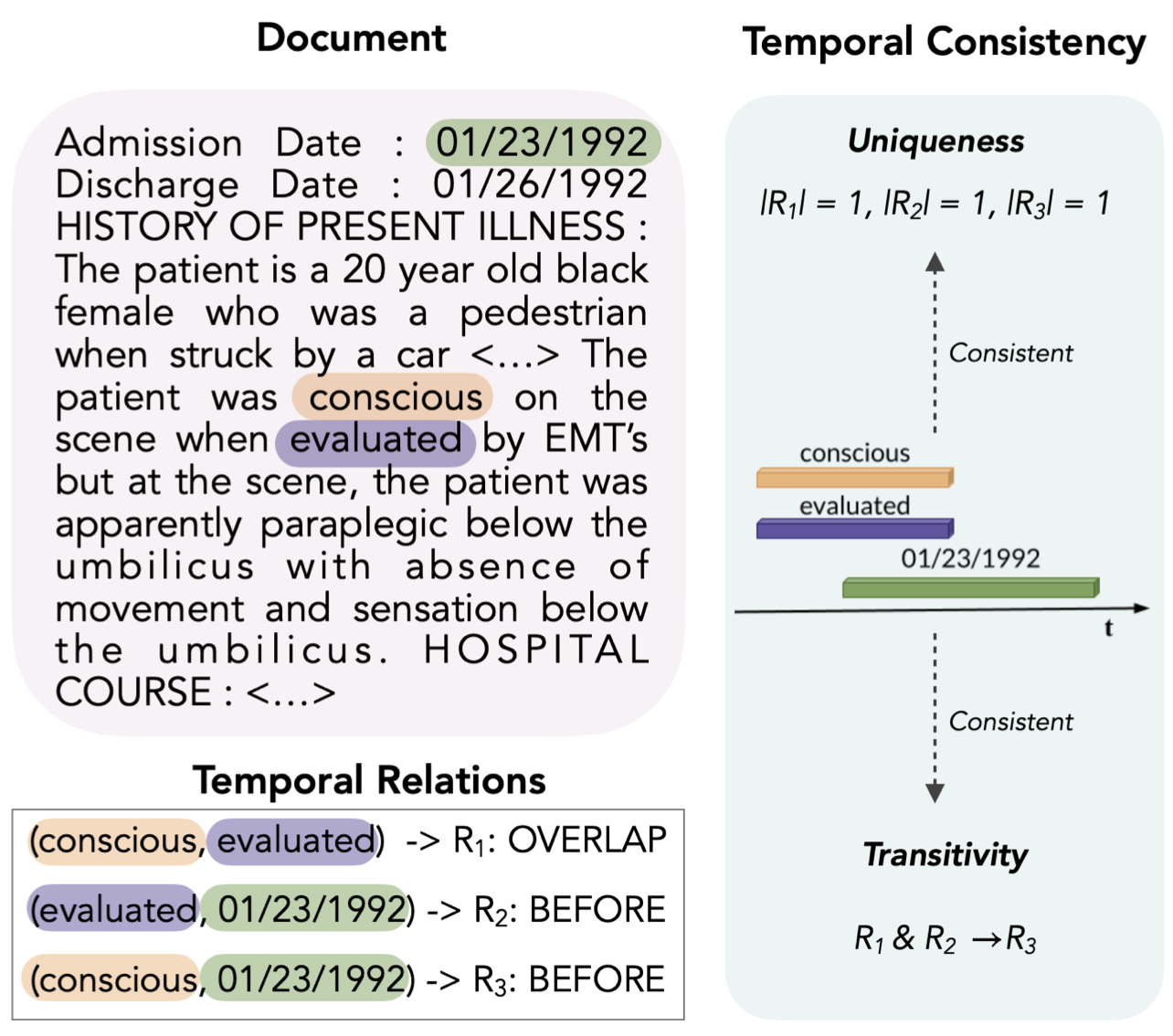 Analysing zero-shot temporal relation extraction on clinical notes using temporal consistencyVasiliki Kougia, Anastasiia Sedova, Andreas Joseph Stephan, and 2 more authorsIn Proceedings of the 23rd Workshop on Biomedical Natural Language Processing, Aug 2024
Analysing zero-shot temporal relation extraction on clinical notes using temporal consistencyVasiliki Kougia, Anastasiia Sedova, Andreas Joseph Stephan, and 2 more authorsIn Proceedings of the 23rd Workshop on Biomedical Natural Language Processing, Aug 2024This paper presents the first study for temporal relation extraction in a zero-shot setting focusing on biomedical text. We employ two types of prompts and five Large Language Models (LLMs; GPT-3.5, Mixtral, Llama 2, Gemma, and PMC-LLaMA) to obtain responses about the temporal relations between two events. Our experiments demonstrate that LLMs struggle in the zero-shot setting, performing worse than fine-tuned specialized models in terms of F1 score. This highlights the challenging nature of this task and underscores the need for further research to enhance the performance of LLMs in this context. We further contribute a novel comprehensive temporal analysis by calculating consistency scores for each LLM. Our findings reveal that LLMs face challenges in providing responses consistent with the temporal properties of uniqueness and transitivity. Moreover, we study the relation between the temporal consistency of an LLM and its accuracy, and whether the latter can be improved by solving temporal inconsistencies. Our analysis shows that even when temporal consistency is achieved, the predictions can remain inaccurate.
@inproceedings{kougia-etal-2024-analysing, title = {Analysing zero-shot temporal relation extraction on clinical notes using temporal consistency}, author = {Kougia, Vasiliki and Sedova, Anastasiia and Stephan, Andreas Joseph and Zaporojets, Klim and Roth, Benjamin}, editor = {Demner-Fushman, Dina and Ananiadou, Sophia and Miwa, Makoto and Roberts, Kirk and Tsujii, Junichi}, booktitle = {Proceedings of the 23rd Workshop on Biomedical Natural Language Processing}, month = aug, year = {2024}, address = {Bangkok, Thailand}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2024.bionlp-1.6/}, doi = {10.18653/v1/2024.bionlp-1.6}, pages = {72--84}, } -
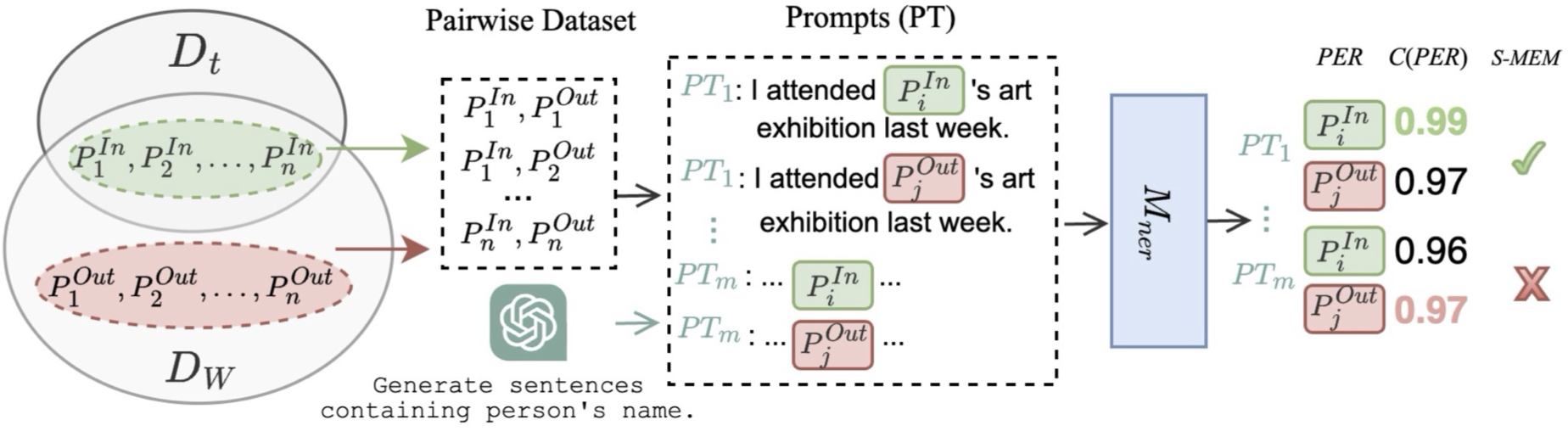 Exploring prompts to elicit memorization in masked language model-based named entity recognitionYuxi Xia, Anastasiia Sedova, Pedro Henrique Luz Araujo, and 3 more authorsAug 2024
Exploring prompts to elicit memorization in masked language model-based named entity recognitionYuxi Xia, Anastasiia Sedova, Pedro Henrique Luz Araujo, and 3 more authorsAug 2024@misc{xia2024exploringpromptselicitmemorization, title = {Exploring prompts to elicit memorization in masked language model-based named entity recognition}, author = {Xia, Yuxi and Sedova, Anastasiia and de Araujo, Pedro Henrique Luz and Kougia, Vasiliki and Nußbaumer, Lisa and Roth, Benjamin}, year = {2024}, eprint = {2405.03004}, archiveprefix = {arXiv}, primaryclass = {cs.CL}, url = {https://arxiv.org/abs/2405.03004}, }
2023
-
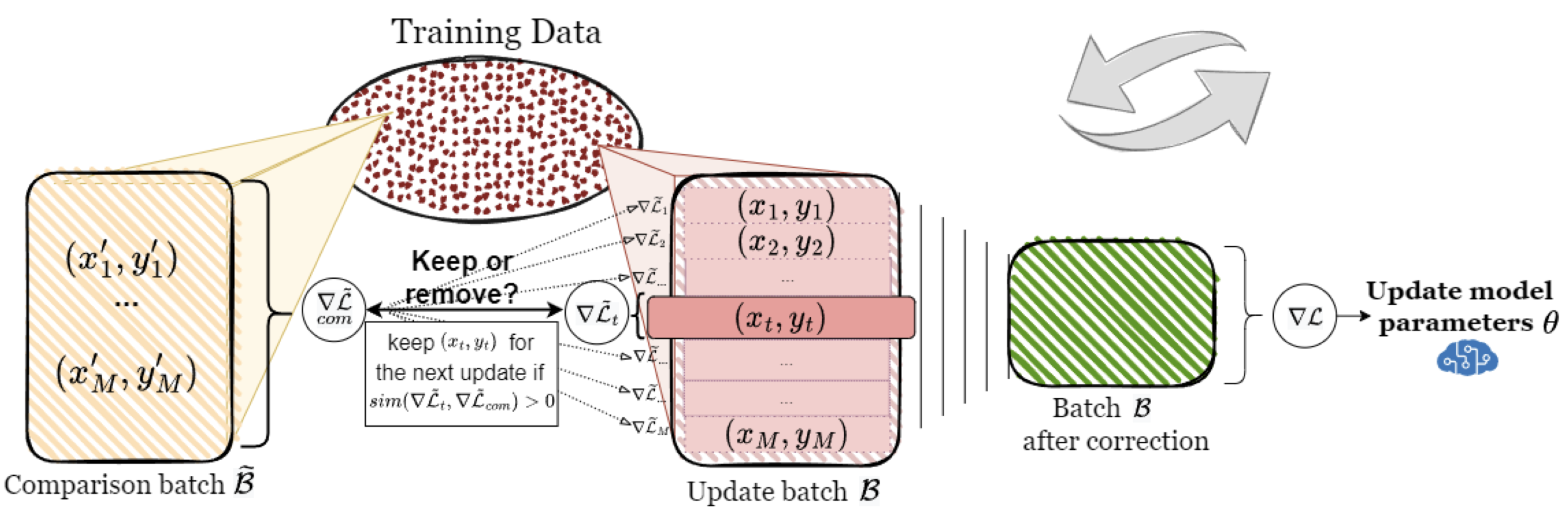 Learning with Noisy Labels by Adaptive Gradient-Based Outlier RemovalAnastasiia Sedova, Lena Zellinger, and Benjamin RothIn Machine Learning and Knowledge Discovery in Databases: Research Track, Aug 2023
Learning with Noisy Labels by Adaptive Gradient-Based Outlier RemovalAnastasiia Sedova, Lena Zellinger, and Benjamin RothIn Machine Learning and Knowledge Discovery in Databases: Research Track, Aug 2023An accurate and substantial dataset is essential for training a reliable and well-performing model. However, even manually annotated datasets contain label errors, not to mention automatically labeled ones. Previous methods for label denoising have primarily focused on detecting outliers and their permanent removal - a process that is likely to over- or underfilter the dataset. In this work, we propose AGRA: a new method for learning with noisy labels by using Adaptive GRAdient-based outlier removal. Instead of cleaning the dataset prior to model training, the dataset is dynamically adjusted during the training process. By comparing the aggregated gradient of a batch of samples and an individual example gradient, our method dynamically decides whether a corresponding example is helpful for the model at this point or is counter-productive and should be left out for the current update. Extensive evaluation on several datasets demonstrates AGRA’s effectiveness, while a comprehensive results analysis supports our initial hypothesis: permanent hard outlier removal is not always what model benefits the most from.
@inproceedings{Sedova_2023, title = {Learning with Noisy Labels by Adaptive Gradient-Based Outlier Removal}, author = {Sedova, Anastasiia and Zellinger, Lena and Roth, Benjamin}, booktitle = {Machine Learning and Knowledge Discovery in Databases: Research Track}, year = {2023}, isbn = {9783031434129}, issn = {1611-3349}, url = {http://dx.doi.org/10.1007/978-3-031-43412-9_14}, doi = {10.1007/978-3-031-43412-9_14}, publisher = {Springer Nature Switzerland}, pages = {237–253}, } -
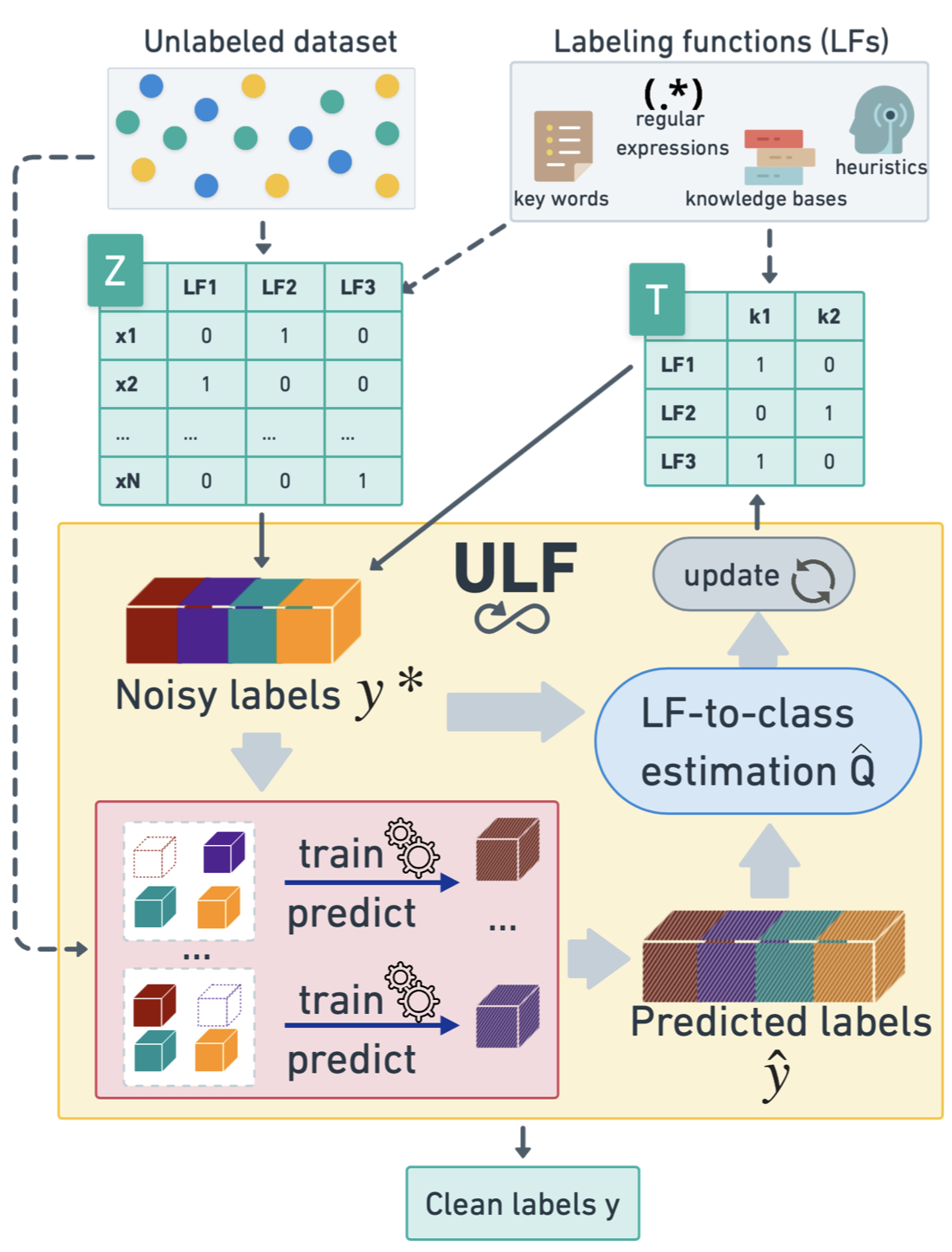 ULF: Unsupervised Labeling Function Correction using Cross-Validation for Weak SupervisionAnastasiia Sedova and Benjamin RothIn Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, Dec 2023
ULF: Unsupervised Labeling Function Correction using Cross-Validation for Weak SupervisionAnastasiia Sedova and Benjamin RothIn Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, Dec 2023A cost-effective alternative to manual data labeling is weak supervision (WS), where data samples are automatically annotated using a predefined set of labeling functions (LFs), rule-based mechanisms that generate artificial labels for the associated classes. In this work, we investigate noise reduction techniques for WS based on the principle of k-fold cross-validation. We introduce a new algorithm ULF for Unsupervised Labeling Function correction, which denoises WS data by leveraging models trained on all but some LFs to identify and correct biases specific to the held-out LFs. Specifically, ULF refines the allocation of LFs to classes by re-estimating this assignment on highly reliable cross-validated samples. Evaluation on multiple datasets confirms ULF‘s effectiveness in enhancing WS learning without the need for manual labeling.
@inproceedings{sedova-roth-2023-ulf, title = {{ULF}: Unsupervised Labeling Function Correction using Cross-Validation for Weak Supervision}, author = {Sedova, Anastasiia and Roth, Benjamin}, editor = {Bouamor, Houda and Pino, Juan and Bali, Kalika}, booktitle = {Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing}, month = dec, year = {2023}, address = {Singapore}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2023.emnlp-main.254/}, doi = {10.18653/v1/2023.emnlp-main.254}, pages = {4162--4176}, } -
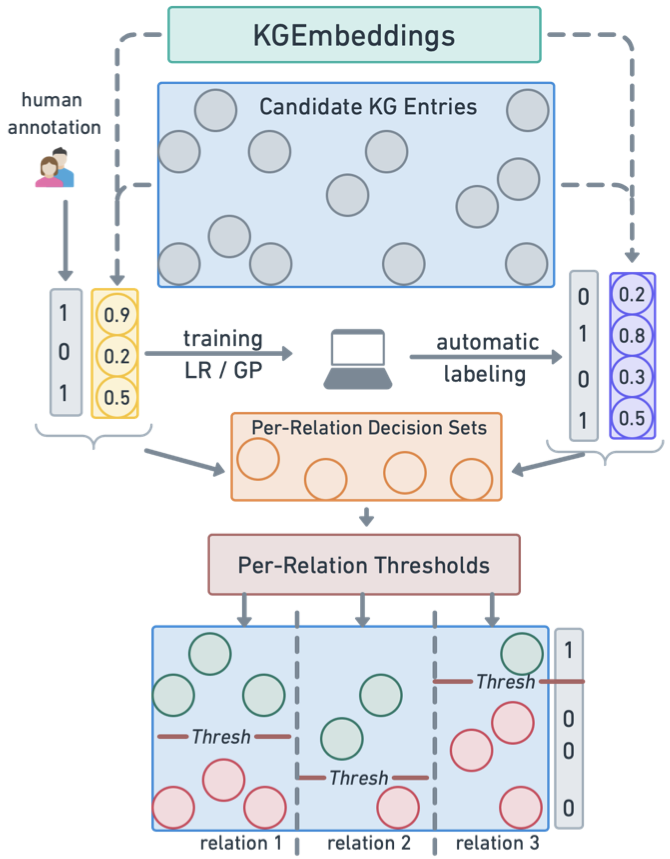 ACTC: Active Threshold Calibration for Cold-Start Knowledge Graph CompletionAnastasiia Sedova and Benjamin RothIn Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Jul 2023
ACTC: Active Threshold Calibration for Cold-Start Knowledge Graph CompletionAnastasiia Sedova and Benjamin RothIn Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Jul 2023Self-supervised knowledge-graph completion (KGC) relies on estimating a scoring model over (entity, relation, entity)-tuples, for example, by embedding an initial knowledge graph. Prediction quality can be improved by calibrating the scoring model, typically by adjusting the prediction thresholds using manually annotated examples. In this paper, we attempt for the first time cold-start calibration for KGC, where no annotated examples exist initially for calibration, and only a limited number of tuples can be selected for annotation. Our new method ACTC finds good per-relation thresholds efficiently based on a limited set of annotated tuples. Additionally to a few annotated tuples, ACTC also leverages unlabeled tuples by estimating their correctness with Logistic Regression or Gaussian Process classifiers. We also experiment with different methods for selecting candidate tuples for annotation: density-based and random selection. Experiments with five scoring models and an oracle annotator show an improvement of 7% points when using ACTC in the challenging setting with an annotation budget of only 10 tuples, and an average improvement of 4% points over different budgets.
@inproceedings{sedova-roth-2023-actc, title = {{ACTC}: Active Threshold Calibration for Cold-Start Knowledge Graph Completion}, author = {Sedova, Anastasiia and Roth, Benjamin}, editor = {Rogers, Anna and Boyd-Graber, Jordan and Okazaki, Naoaki}, booktitle = {Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers)}, month = jul, year = {2023}, address = {Toronto, Canada}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2023.acl-short.158/}, doi = {10.18653/v1/2023.acl-short.158}, pages = {1853--1863}, }
2021
-
 Knodle: Modular Weakly Supervised Learning with PyTorchAnastasiia Sedova, Andreas Stephan, Marina Speranskaya, and 1 more authorIn Proceedings of the 6th Workshop on Representation Learning for NLP (RepL4NLP-2021), Aug 2021
Knodle: Modular Weakly Supervised Learning with PyTorchAnastasiia Sedova, Andreas Stephan, Marina Speranskaya, and 1 more authorIn Proceedings of the 6th Workshop on Representation Learning for NLP (RepL4NLP-2021), Aug 2021Strategies for improving the training and prediction quality of weakly supervised machine learning models vary in how much they are tailored to a specific task or integrated with a specific model architecture. In this work, we introduce Knodle, a software framework that treats weak data annotations, deep learning models, and methods for improving weakly supervised training as separate, modular components. This modularization gives the training process access to fine-grained information such as data set characteristics, matches of heuristic rules, or elements of the deep learning model ultimately used for prediction. Hence, our framework can encompass a wide range of training methods for improving weak supervision, ranging from methods that only look at correlations of rules and output classes (independently of the machine learning model trained with the resulting labels), to those that harness the interplay of neural networks and weakly labeled data. We illustrate the benchmarking potential of the framework with a performance comparison of several reference implementations on a selection of datasets that are already available in Knodle.
@inproceedings{sedova-etal-2021-knodle, title = {Knodle: Modular Weakly Supervised Learning with {P}y{T}orch}, author = {Sedova, Anastasiia and Stephan, Andreas and Speranskaya, Marina and Roth, Benjamin}, editor = {Rogers, Anna and Calixto, Iacer and Vuli{\'c}, Ivan and Saphra, Naomi and Kassner, Nora and Camburu, Oana-Maria and Bansal, Trapit and Shwartz, Vered}, booktitle = {Proceedings of the 6th Workshop on Representation Learning for NLP (RepL4NLP-2021)}, month = aug, year = {2021}, address = {Online}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2021.repl4nlp-1.12/}, doi = {10.18653/v1/2021.repl4nlp-1.12}, pages = {100--111}, }
2017
- Topic Modelling in Parallel and Comparable Fiction Texts (the case study of English and Russian prose)Olga Mitrofanova and Anastasiia SedovaIn Proceedings of the International Conference IMS-2017, Saint Petersburg, Russian Federation, Aug 2017
The paper is devoted to processing parallel and comparable corpora by means of topic modelling. We focus our attention on Russian and English parallel and comparable texts. We use Latent Dirichlet Allocation (LDA) algorithm for building topic models of fiction texts, evaluation of compatibility for the original text and its translation(s), selection of possible translation equivalents.
@inproceedings{10.1145/3143699.3143734, author = {Mitrofanova, Olga and Sedova, Anastasiia}, title = {Topic Modelling in Parallel and Comparable Fiction Texts (the case study of English and Russian prose)}, year = {2017}, isbn = {9781450354370}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, url = {https://doi.org/10.1145/3143699.3143734}, doi = {10.1145/3143699.3143734}, booktitle = {Proceedings of the International Conference IMS-2017}, pages = {175–180}, numpages = {6}, keywords = {English, Fiction, Parallel and Comparable Texts, Russian, Text Corpora, Topic Modelling}, location = {Saint Petersburg, Russian Federation}, series = {IMS2017}, }